DNA und Gene
Als Genom bezeichnet man die Gesamtheit aller Chromosomen in einer Zelle. Bei Eukaryoten liegen die Chromosomen im Zellkern. Sie bestehen aus einem Zentrum und zwei Chromatiden, wobei das Zentrum die Chromatiden unterteilt. Ein Chromatid besteht aus Chromatin, welches wiederum aus einem Gewirr von DNA-Strängen und Proteinen besteht.
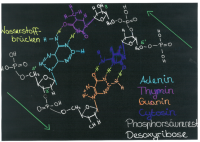
Die Desoxyribonukleinsäure (DNS), im Englischen „deoxyribonucleic acid“ (DNA) besteht aus einem Doppelstrang und wird dadurch auch als Doppelhelix beschrieben. Die DNA ist zusammengesetzt aus vielen Nukleotiden. Ein Nukleotid besteht aus drei Bestandteilen: Der Phosphorsäure, dem Zucker Desoxyribose und aus einer der vier Basen. Dabei bilden die Phosphorsäure und der Zucker das Rückgrat. Die Basen Adenin (A), Thymin (T), Cytosin (C) und Guanin (G), würden die sogenannten Sprossen in einer Leiter bilden. Die Nukleotiden-stränge werden durch Wasserstoffbrückenbindungen zusammengehalten, wobei A & T bzw. C & G eine Verbindung eingehen. Dadurch entsteht der Doppelstrang. Ebenfalls befinden sich die Gene auf der DNA. Sie sind Abschnitte auf der DNA und aus Basen aufgebaut. Diese werden bei der Proteinbiosynthese zu Proteinen umgewandelt, um dann ihre Funktion zu gewährleisten. Die RNA, auch Ribonukleinsäure genannt, ähnelt der DNA. Trotzdem gibt es Unterschiede: Erstens kommt bei der RNA der Zucker Ribose vor, anstatt Desoxyribose und zweitens ist die RNA kein Doppelstrang. Ebenfalls wird die Base Uracil anstatt Thymin benutzt und die RNA-Moleküle sind kürzer als die DNA-Moleküle.
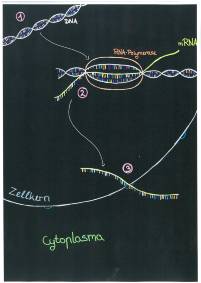
Die Proteinbiosynthese ist in zwei Schritte aufgeteilt. In die Transkription und in die Translation. Kurzgefasst kann man sagen, dass bei der Transkription die DNA (s. Abb. 13: Transkription im Zellkern, Nr. 1) in seine zwei Einzelstränge zerlegt wird und eine komplementäre Kopie von einem der beiden Stränge entsteht (s. Abb. 13: Nr. 2). Diese Kopie nennt man dann mRNA (s. Abb. 13: Nr. 3). Das m steht dabei für „messenger“. Beim genauen Prozess werden die Wasserstoffbrückenbindungen der DNA von der RNA-Polymerase gebrochen (Entspiralisierung der DNA). Hierbei gibt der Promoter den Startpunkt an und der Terminator den Endpunkt. Diese Punkte sind wichtig, damit die RNA-Polymerase weiß, ab wann und bis wo sie die Wasserstoffbrückenbindungen trennen muss. Während des Prozesses werden die Nukleotide des sogenannten Codogenem-Strangs von der RNA-Polymerase abgelesen und die komplementäre mRNA wird zusammengefügt (s. Abb. 13: Nr. 2). Also wenn z.B. die Basenabfolge bei dem Codogenem-Strang ATAGC ist, entsteht auf der mRNA die Basenabfolge UAUCG. Achtung: Bei der RNA wird anstatt Thymin Uracil (U) verwendet. Nachdem die RNA-Polymerase den Terminator Bereich erreicht hat, löst es sich von der DNA und gibt die mRNA frei (s. Abb. 13: Nr. 3).
Bevor es zum nächsten Schritt, der Translation, kommen kann, müssen bei den Eukaryoten aus der mRNA noch unwichtige Abschnitte entfernt werden. Dieser Prozess wird RNA-Prozessierung genannt. Hierbei werden die Introns, die unwichtigen Abschnitte, herausgeschnitten und entfernt. Die verbliebenen Exons, welche die wichtigen Informationen besitzen, fügen sich danach wieder zu dem RNA-Molekül mRNA zusammen. Bei den Prokaryoten, also den einzelligen Lebewesen, wird direkt nach der Transkription die Translation eingeleitet.
Bei der Translation werden jeweils drei Basenpaare (auch als Triplett oder Codon bezeichnet) zu einer Aminosäure übersetzt. Aminosäuren sind Bestandteile von den entstehenden Proteinen. Hierbei wird die mRNA, die tRNA mit einer Aminosäure und ein Ribosom benötigt. Das t bei der tRNA steht für „transfer“, was Überträger bedeutet. Das Ribosom besteht aus einer kleineren und aus einer größeren Untereinheit und besitzt außerdem drei Stellen, zwei Bindungsstellen (A- und P-Stelle) und eine Ausgangsstelle, die E-Stelle. Die Translation geschieht, indem sich das eine Ende der mRNA an die kleine Untereinheit von dem Ribosom bindet. Daraufhin bindet sich die tRNA, mit der Aminosäure anhängend, an drei Basenpaare der mRNA, mit Hilfe eines Anticodons. Die Bindung der mRNA und der tRNA findet an der A-Stelle statt. Danach tritt die zweite Hälfte des Ribosoms hinzu. Daraufhin wird die tRNA an die nächste Stelle, durch die Verschiebung eines Tripletts, an die P-Stelle transportiert.
.jpg/picture-200?_=16170cca010)
An der nun frei gewordenen A-Stelle wird eine neue tRNA mit einer Aminosäure gebunden (s. Abb. Translation am Ribosom, Nr. 1). Die Aminosäuren auf den jeweiligen Bindungsstellen sind sich nun so nah, dass sie nun durch eine Peptidbindung eine Bindung miteinander eingehen (s. Abb. Nr. 2). Nun befinden sich beide Aminosäuren an der A-Stelle und die tRNA an der P-Stelle besitzt keine Aminosäure mehr. Danach wird die mRNA wieder um ein Triplett verschoben und die tRNA ohne Aminosäure wird an der E-Stelle ausgeworfen (s. Abb. Nr. 3). Die A-Stelle ist nun wieder frei, da sich dessen tRNA mit den beiden Aminosäuren nun wieder an der P-Stelle befindet. Somit wird eine neue tRNA an die A-Stelle gebunden. Jetzt wiederholt sich der Prozess bis zum sogenannten Stopcodon. Die entstandene Aminosäuren Kette ist das Protein, welches nun seine Aufgabe ausführen kann und somit seinem Merkmal eine Form geben kann.